





今日DeepMind資深工程師黃士傑在人工智慧年會中,以「AlphaGo-深度學習與強化學習的勝利」為主題分享AlphaGo研發成果。整場演講中,黃士傑不僅分享了背後的技術,也透露了Deepminmd團隊的科學精神與研究理念。
2019.11.28新消息:代表人類出戰AI棋手AlphaGo,韓國棋王李世乭宣佈退役
技術:AlphaGo Zero展示了強化學習的巨大潛力
黃士傑強調,AlphaGo Zero不使用人類的資料、指導或規則以外的領域知識,「一切都從零開始,一開始AlphaGo自己再亂下棋,」但是Alpha Zero三天就以100:0成果打敗李世乭版本的AlphaGo,「超越人類幾千年圍棋研究的歷程」。
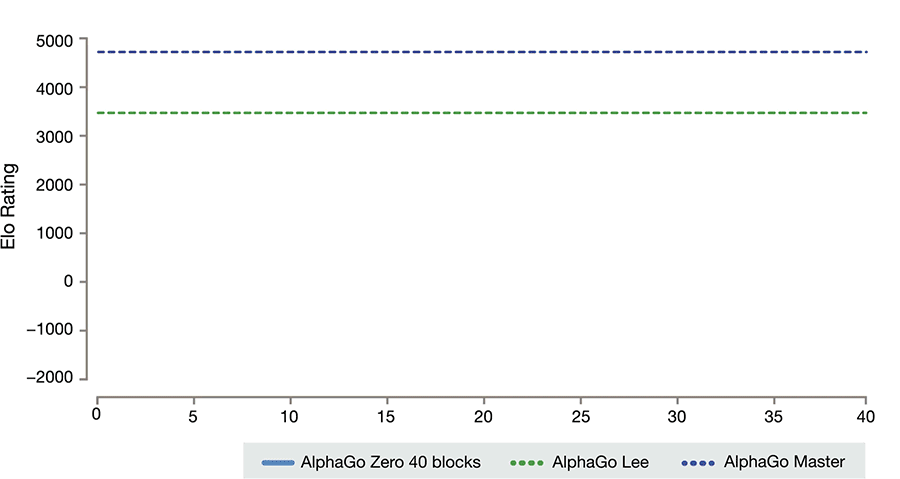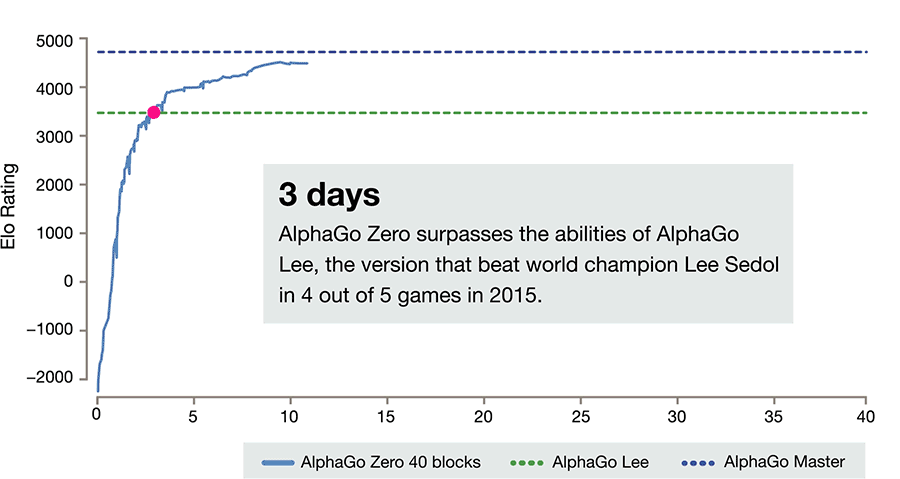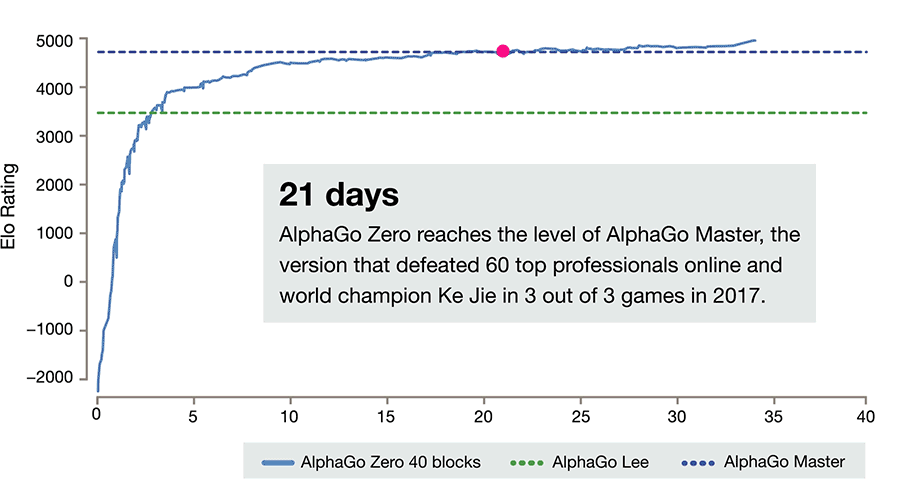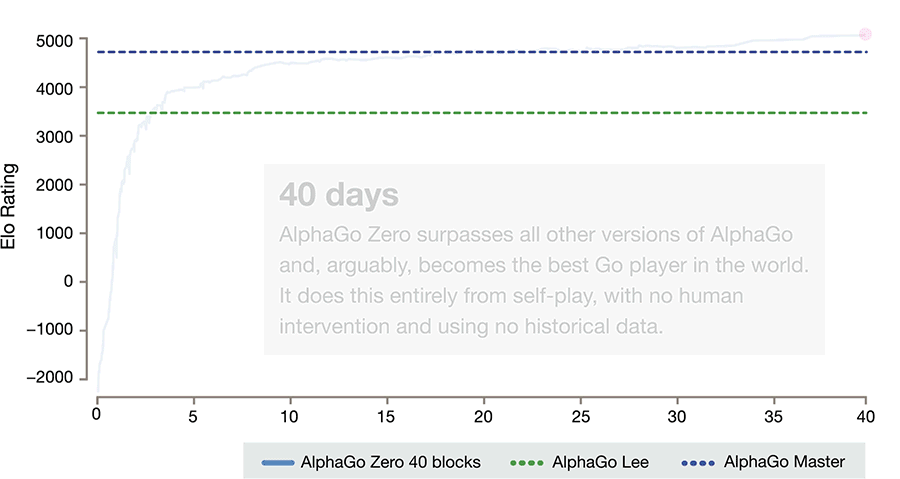
黃士傑指出,AlphaGo Zero和先前版本主要的差異在於1. AlphaGo Zero 結合了決策網絡(Policy Network:選擇下一步棋的位置)與價值網絡(Value Network:預測每一個位置上決定的勝者)2.移除Rollouts(快速隨機下棋法,從棋盤位置預測哪個棋手贏面較大),依靠神經網絡評估下棋位置。同時也把RL Training Pipeline效能極大化。
而這些改變也讓AlphaGo Zero效能更好,Zero版本只需四個TPU就可以運行。黃士傑強調硬體的重要性,尤其是TPU,「Google給了充足的資源,讓團隊自由地嘗試各種點子。」
精神:推動全球人工智慧領域的進步
而在演講中,黃士傑也透露出Deepmind團隊的科學家精神與科學分享的胸襟。這和一個棋手有關:樊麾。
樊麾是誰?他是中國出生的法國職業棋手,也是人類史上第一個被人工智慧打敗的棋士。2015年10月,樊麾受邀與AlphaGo競賽,結果,AlphaGo以5:0全勝的紀錄擊敗樊麾,成為世界上第一個於十九路棋盤上,被電腦擊敗的職業棋手。打敗樊麾後,黃士傑非常想和外界分享這個驚人事件,不過Deepminmd對整件事情下了「禁聲令」,不能對外說明。
「我們憋了好幾個月!」原來,Deepmind公司要黃士傑先完成論文,把研究成果投稿到《自然》(Nature)(《自然》規定在論文未發表前,不得對外說明,否則不予接受。)
當時黃士傑對此非常疑惑?「為什麼我們要花時間寫論文?不是應該好好準備和李世乭比賽?」再來,「把研究成果寫成論文發表,那所有秘密不就公開了嗎?」
不過Deepmind團隊的想法是,「我們是在做研究!科學的精神就是互相『分享』,推動整個領域進步。」於是團隊先把論文完成,2016年1月《自然》線上發表了這篇論文:Mastering the game of Go with deep neural networks and tree search。雖然這一段只是整場演場中的一小部分,但對於科技圈來說卻是一個極佳的典範。
科技創新不是鎖在實驗室,而是化成知識快速在外界傳遞,促成更多的研究者前仆後繼。
目標:人工智慧是人類的工具而非威脅
黃士傑指出現在的人工智慧離接近人類的「強」人工智慧還有很長的距離(far-away),至於這個距離有多少年?黃士傑沒有給出自己的看法,不過他強調,人工智慧離擁有「自我意識」的本質更加遙遠,因此無所不能的人工智慧,不會在短期內出現,「電影終究只是電影」。
AlphaGo從首爾比賽到烏鎮,對於外界來說,都是人類與人工智慧的對弈。而在烏鎮的柯潔大戰AlphaGo時,業界幾乎沒有人認為人類能贏,也就是說科技圈早就知道這是一場人類必輸的比賽,那為何AlphaGo還要打老遠跑到中國和柯潔對戰?
黃士傑說,在第一場在首爾與南韓棋王李世乭的戰役,重點在「輸贏」,氣氛緊張嚴肅,但第二場在烏鎮對戰中國旗手柯潔,重點在於人機共同探索圍棋,這時人工智慧的價值在於「幫助」棋手擴張思路 ,因此氣氛變得愉悅。
這也是Deepmind要傳達給外界的理念:人工智慧是人類的工具而非威脅,破除外界對於人工智慧統治人類的迷思想法。



