


哈布斯堡王朝 (Habsburg dynasty) 在歐洲曾經是不可一世的存在。在長達數百年的時間裡,他們的血脈遍佈西班牙、奧地利乃至半個歐洲。但是這個家族幾乎每個人都有一個明顯的特徵:異常突出、厚重的下巴、以及下垂的嘴唇。這是後來廣為人知的「哈布斯堡下巴」(Habsburg jaw)。

當時哈布斯堡家族為了鞏固權力、確保將龐大的領土和財富世世代代都牢牢鎖在家族內部,居然用了一個現在看起來令人不可思議、細思極恐的辦法:近親通婚 (inbreeding)。叔叔迎娶姪女,表兄妹結合,在好幾個世代當中,這種聯姻被哈布斯堡家族視為保持「血統純正」的必要手段。
他們確實成功地將權力和財富留在了家族中,但也開始將有害的遺傳隱性基因不斷累積和放大。大家可以想想,近親通婚要是這樣持續 10 代以上,會發生什麼事情?這個歷史上赫赫有名的家族,就這樣幫我們做了一個肉身實驗。
後來,事實證明「哈布斯堡下巴」只是遺傳問題的冰山一角,隨之而來的是一系列更嚴重的狀況:高夭折率、癲癇、智力缺陷。這個詛咒一直延續到西班牙哈布斯堡王朝的末代國王卡洛斯二世。他身患多種遺傳疾病,終生殘疾,最後無法留下任何後代。
一個曾經統治世界的王朝,就這樣因為這種「自我參照」和「基因多樣性的喪失」,走向了衰敗。
AI將重演「哈布斯堡下巴」詛咒?
沒想到,數百年後在 AI 這個領域,這個古老的詛咒重新上演。
AI 產業已經開始面臨一個嚴重的問題:我們快要用完所有「可用的公開資料」了。根據估計,2026-2028 這段時間,AI 公司們就會把所有網路上的公開資料給爬完、用完。這聽起來有點不可思議,畢竟對我們人類來說,網路上的資料感覺就像是有無限多一樣,怎麼看也看不完,怎麼可能有用完的一天呢?但這完全是因為我們身為人類只有一個小小的腦袋,一生都裝不了太多的資訊。
所以,現在 AI 公司在訓練 AI 時,基本上都是讓 AI 把網路上的資料「反覆看過好幾遍」。沒有任何一個人類可以做到這種事情,這完全是因為過去幾十年電腦儲存和運算能力的持續增加,終於讓原本難以想像的龐大公開資料,也能一次被 AI 消化完畢,因此現在幾間大型的 AI 公司都面臨了資料短缺的問題。
你或許會說,可是人類會持續產生更多的資料啊!沒有錯,但這些新產生的資料邊際效益並沒有這麼大,說得直白一點,人類產生出新知識的速度並沒有這麼快(實際上是非常慢),而且大多數新產生出來的資料對於 AI 的進步已經沒有幫助了(想想你每天發的廢文吧)。而且而且,就算好不容易產生出來對訓練 AI 有用的新知識,這個新知識也是一瞬間就被狼吞虎嚥的 AI 吃掉了。
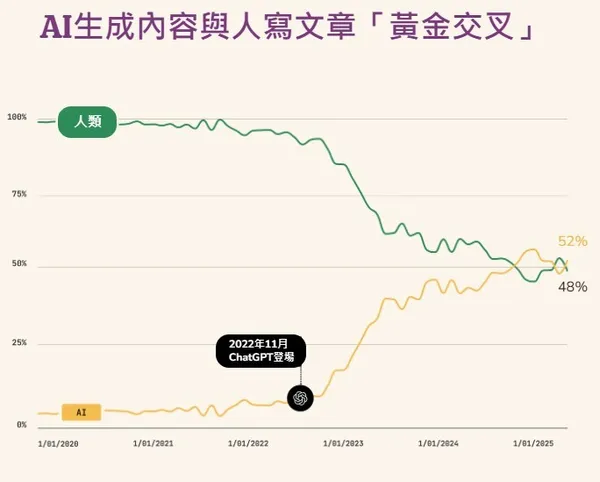
所以。頂尖的 AI 模型已經「吃掉」了網路上幾乎所有唾手可得的高品質文字和圖像。於是,為了讓 AI 繼續進化、變得更強,大家被迫轉向一個看似合理、卻暗藏風險的解決方案: 讓 AI 去學習「由 AI 自己生成的資料」 。
這在 AI 領域,被稱為「合成數據」(synthetic data)。 這在哈布斯堡王朝,被稱為「近親通婚」。
過去兩年,有幾篇學術論文已經證實,一旦我們這樣子做,經過幾次迭代之後,AI 就會變得越來越糟糕,甚至到了完全不能用的地步。研究人員因此給了這個現象一個暱稱: 「哈布斯堡效應」。或者更專業一點的學術名稱:「模型崩潰」(model collapse) 。
這個過程,就像你拿著一台影印機,去影印「上一次影印出來的影本」,每次都拿新印出來的文件再去影印,反覆這樣操作幾次之後,你會開始發現,越印越糊。
「原始的資料」其實像是一幅充滿了豐富細節、生動色彩、甚至帶有一些小小瑕疵的原創風景畫。當中這些「瑕疵」和「罕見筆觸」(例如冷門知識、幽默感、獨特的寫作風格等等)其實代表了非常重要的「基因多樣性」。
第一次影印(AI 第 1 代): AI 學習了這幅畫,並生成了一份「影本」(合成數據)。這份影本非常出色,99.9% 接近原版。但是,AI 作為一個統計模型,在訓練的過程當中,它會不自覺地「取平均值」。它會稍微「平滑」掉那些它認為不重要的「瑕疵」(罕見知識),並稍微「強化」那些最常見的特徵(主流觀點)。
第二次影印(AI 第 2 代): 現在,下一代 AI 拿去學習的,是那份「第一次的影本」。它會學到那個 99.9% 準確、但「稍微平滑過」的版本。然後,它會在這個基礎上「再次取平均值」。
第 N 次影印(AI 第 N 代): 這個過程不斷重複。AI 學習 AI 的輸出,再學習 AI 的 AI 的輸出⋯⋯ 這就是我們所謂的「自我參照迴圈」(Self-Referential Loop)。

經過 N 代「近親通婚」後,AI 開始顯現出與哈布斯堡王朝驚人相似的衰敗症狀:
1. 特徵放大與平庸化 (the "jaw"): AI 變得極度「無聊」且「可預測」。就像「哈布斯堡下巴」這個特徵在每一代都被強化,AI 最「平均」、最「主流」的特徵也被無限放大。所有原創的、古怪的、有創意的「基因」(數據多樣性)都在這個「反覆影印」中被消磨殆盡。最終,AI 只會生成那些最「四平八穩」、最「政治正確」、但也最沒有靈魂的內容。
2. 遺忘「尾部」 (forgetting the "tails"): 真實的世界充滿了「長尾」數據,也就是那些大量罕見但真實的知識。AI 在「取平均」的過程中,會最先丟棄這些「尾部」知識,因為它們不常出現。幾代之後,AI 會徹底「遺忘」現實世界的多樣性。它會變得越來越「純粹」,但也越來越「無知」。
3. 錯誤放大 (amplified bias): 如果 AI (Gen 1) 犯了一個小錯誤(例如,它在 1% 的時間裡認為「鯊魚是哺乳動物」)。AI (Gen 2) 會把這個「1% 的錯誤」當作「真實資料」來學習。幾代之後,這個小錯誤會被不斷放大,直到 AI (Gen N) 堅定地認為「鯊魚絕對是哺乳動物」。
4. 王朝終結 (total collapse): 研究證明了這個崩潰的終點:如果完全依賴合成數據,模型最終會「忘記」語言和現實的基本結構,其輸出會退化成毫無意義、不斷重複的胡言亂語 (gibberish)。
這或許可以稱作 AI 的「哈布斯堡詛咒」吧。一個古老王朝為了維持血統純正而走向滅亡的故事,竟在數百年後,在訓練 AI 時重現。
所以,這個「詛咒」已不再是理論。它是 OpenAI、Google 和 Anthropic 這些頂尖 AI 公司都正在拼命解決的核心難題。現在 AI 撞上的這道「數據之牆」,其實就是其中一道阻礙擴展定律繼續發揮強大效用的牆。
因此大家現在別無選擇,必須想辦法使用「合成數據」來跨越數據之牆,讓 AI 的能力繼續進步。
因此,接下來的 AI 競賽,至少在數據層面上,關鍵已經不是誰能造出更大的模型,而是誰能率先掌握「AI 基因工程」:
如何在合成數據時,保持最大的「基因多樣性」?
如何確保每一代訓練中,都混入一定比例「新鮮的、真實的人類血液」(新的人類資料),以避免「近親通婚」?
歷史在這邊也給了我們重要的啟發,一個封閉的、只靠自我參照的系統,無論它一開始多麼厲害,最終都將走向僵化和衰敗。AI 想要通往更廣闊的未來,就絕不能切斷與豐富、混亂、甚至充滿「瑕疵」的真實世界的連結。也許就跟人一樣,我們不能總是在我們的腦袋裡或是小圈圈裡想事情,還是要持續接觸外面的世界。
因此我認為,人類在演化論累積下來的經驗和基礎,將會是下一代 AI 突破的重要關鍵。
本文授權轉載自程世嘉Facebook
